Notes on training BERT from scratch on an 8GB consumer GPU
I trained a BERT model (Devlin et al, 2019) from scratch on my desktop PC (which has a Nvidia 3060 Ti 8GB GPU). The model architecture, tokenizer, and trainer all came from Hugging Face libraries, and my contribution was mainly setting up the code, setting up the data (~20GB uncompressed text), and leaving my computer running. (And making sure it was working correctly, with good GPU utilization.)
- The code is available as a Jupyter notebook, here.
- The data is available as a Hugging Face dataset, here.
The training of large language models is generally associated with GPU or TPU clusters, rather than desktop PCs, and the following plot illustrates the difference between the compute resources I used to train this model, and the resources used to train the original BERT-base model.
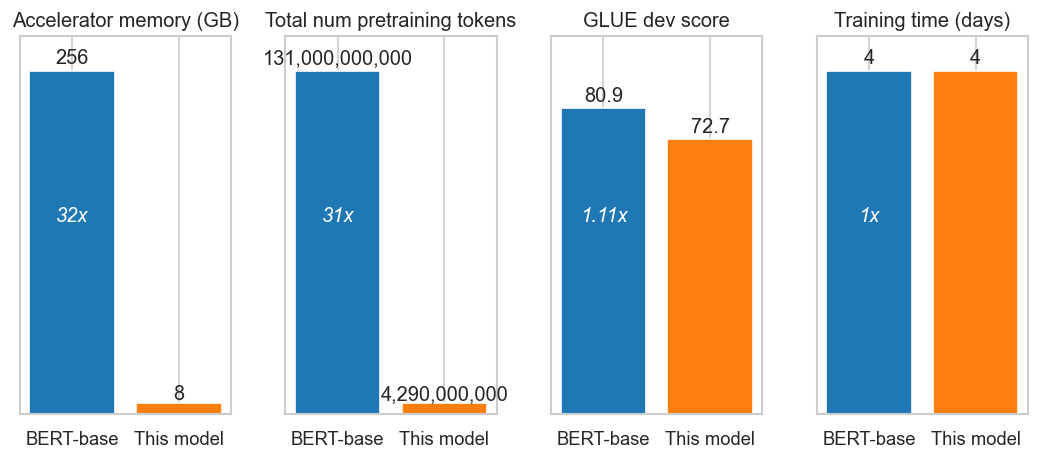
Although both BERT-base and this model were trained for the same amount of time, BERT-base saw ~30x more tokens of text, (BERT-base saw ~40 epochs of its training data, while this model saw just a single epoch of its training data).
The GLUE dev-set score is shown in the plot above, to give an idea of how well the model performs at natural language tasks. Fine-tuning on GLUE took ~12 hours in total (on top of the 4 days / ~100 hours of pretraining). The following table shows the GLUE-dev results in more detail:
| Model | MNLI (m/mm) | SST-2 | STSB | RTE | QNLI | QQP | MRPC | CoLA | Average |
|---|---|---|---|---|---|---|---|---|---|
| This model | 79.3/80.1 | 89.1 | 61.9 | 55.9 | 86.3 | 86.4 | 74.8 | 41.0 | 72.7 |
| BERT-Base* | 83.2/83.4 | 91.9 | 86.7 | 59.2 | 90.6 | 87.7 | 89.3 | 56.5 | 80.9 |
*BERT-Base refers to a fully trained BERT model, the results are taken from Cramming (Geiping et al, 2022).
While we can see that BERT-Base performed better at every task; the results for “this model” would have been very good (possibly SOTA for a few tasks) in early 2018.
No hyperparameter tuning was carried out. No special techniques were used to improve the training. Optimizer and learning rate schedule were guided by Cramming (Geiping et al, 2022), but the model architecture changes and other suggestions in Cramming were not used. I did a couple of smaller training runs first (~1-12 hours).
I was able to monitor training remotely, using Weights & Biases.
This endeavor was inspired by Cramming (Geiping et al, 2022), a paper on how to train well-performing BERT models, on modest compute resources (in only 24 hours).
Plots from the 100 hours training run
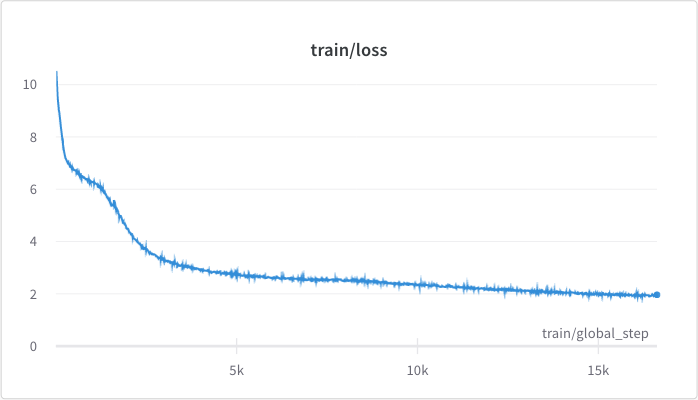 <figcaption>The pre-training loss.</figcaption>
<figcaption>The pre-training loss.</figcaption>
).](/assets/posts/bert-from-scratch/learning_rate.png) <figcaption>The learning rate schedule, recommended by Cramming (Geiping et al, 2022).</figcaption>
<figcaption>The learning rate schedule, recommended by Cramming (Geiping et al, 2022).</figcaption>
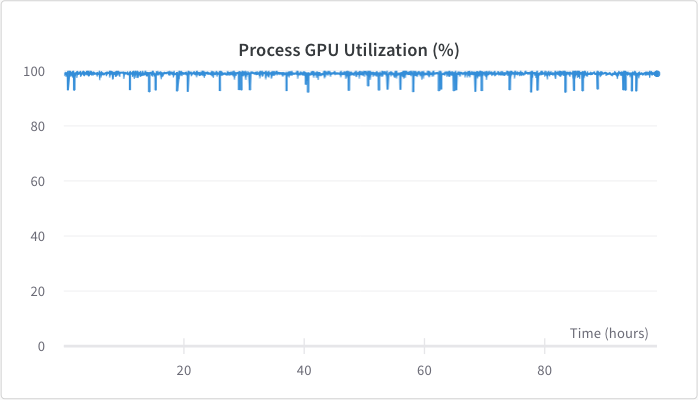 <figcaption>GPU utilization was around 98%.</figcaption>
<figcaption>GPU utilization was around 98%.</figcaption>
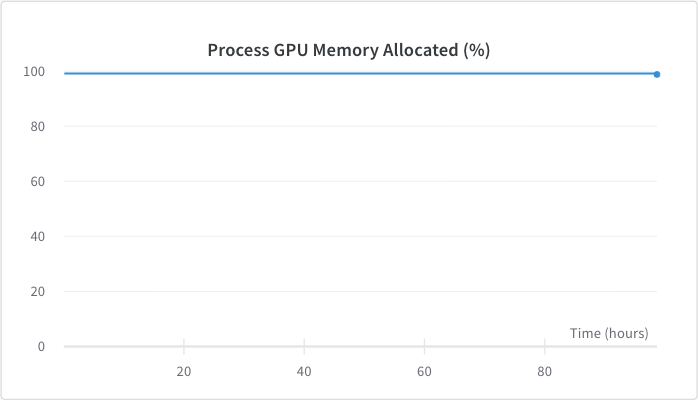 <figcaption>GPU memory usage was around 98%, this was achieved by adjusting the batch size.</figcaption>
<figcaption>GPU memory usage was around 98%, this was achieved by adjusting the batch size.</figcaption>
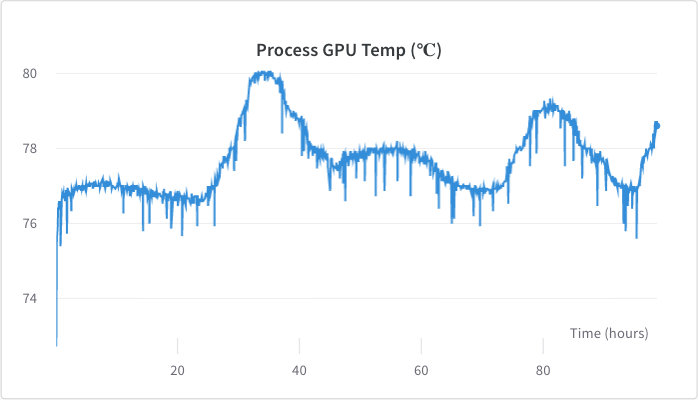 <figcaption>GPU temperature stayed between 76 - 80 degrees celsius, with a higher temperature on hotter days.</figcaption>
<figcaption>GPU temperature stayed between 76 - 80 degrees celsius, with a higher temperature on hotter days.</figcaption>
References:
- Geiping, Jonas, and Tom Goldstein. “Cramming: Training a Language Model on a Single GPU in One Day.” arXiv preprint arXiv:2212.14034 (2022). URL https://arxiv.org/abs/2212.14034.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 [cs], May 2019. URL http://arxiv.org/abs/1810.04805.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. arXiv:1706.03762 [cs], December 2017. URL http://arxiv.org/abs/1706.03762.
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI, https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf