How to implement visual content search in video using OpenAI's CLIP model, in Python
By the end of this post, we’ll be able to search for specific visual content within a video by describing it in words. For instance, we could search for “a man hanging from a boom barrier,” and the system would return the locations in the video where a it’s likely that a man is hanging from a boom barrier.
query = "A man hanging from a boom barrier"
frame, similarities = get_most_similar_frame(query)
display_frame(frame)
plot_search(query, similarities)

We do indeed find a frame of video where a man is hanging from a boom barrier.
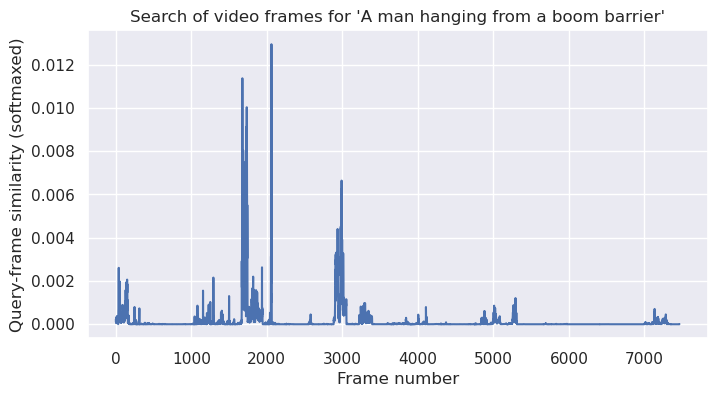
This plot shows how likely the model thinks the frames of video are to contain the content of the query.
We’ll use OpenAI’s open-source deep learning model, CLIP. Audio will be ignored during the search. GitHub repo for this post here.
How does CLIP work?
CLIP is a state-of-the-art deep learning model that has the remarkable ability to encode both text and image content into the same high-dimensional vector space. This means that it can represent an image of a dog and the text “A picture of a dog” as vectors that are expected to be close together in terms of cosine similarity. The closer the vectors, the more similar the content they represent. Conversely, if we were to encode a different image, such as one of a cat, into a vector, it would be farther away from the vectors of the dog image and text. This distance reflects the dissimilarity between the content they represent. By placing similar content vectors closer together and dissimilar content vectors farther apart, CLIP enables content-based retrieval and classification.
Since a video is just a series of images, we can use this model to search over the visual content of a video using text.
Let’s go
First let’s import the packages we need and load the model (its parameters are ~340mb).
from pathlib import Path
import clip
import cv2
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from PIL import Image
from tqdm import tqdm
sns.set_theme()
torch.set_printoptions(sci_mode=False)
data_dir = Path("data_dir")
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device) # will download ~340mb model
Turning images and text into vectors:
The CLIP model we are using turns images into vectors of size 512, and pieces of text also into vectors of size 512. As mentioned above, we expect images and pieces of text that have similar content to have “similar” vectors. Here’s a concrete example:
image = preprocess(Image.open("dog.jpeg")).unsqueeze(0).to(device)
dog_text = clip.tokenize(["a photo of a dog"]).to(device)
cat_text = clip.tokenize(["a photo of a cat"]).to(device)
misc_text = clip.tokenize(["red green yellow"]).to(device)
with torch.no_grad():
image_vector = model.encode_image(image)
dog_text_vector = model.encode_text(dog_text)
cat_text_vector = model.encode_text(cat_text)
misc_text_vector = model.encode_text(misc_text)
print(f"{image_vector.shape = }")
print(f"{dog_text_vector.shape = }")
print(f"{cat_text_vector.shape = }")
print(f"{misc_text_vector.shape = }")
image_vector.shape = torch.Size([1, 512])
dog_text_vector.shape = torch.Size([1, 512])
cat_text_vector.shape = torch.Size([1, 512])
misc_text_vector.shape = torch.Size([1, 512])
dog_similarity = torch.cosine_similarity(image_vector, dog_text_vector).item()
cat_similarity = torch.cosine_similarity(image_vector, cat_text_vector).item()
misc_similarity = torch.cosine_similarity(image_vector, misc_text_vector).item()
print(f"dog similarity: {dog_similarity:.2f}")
print(f"cat similarity: {cat_similarity:.2f}")
print(f"misc similarity: {misc_similarity:.2f}")
dog similarity: 0.28
cat similarity: 0.20
misc similarity: 0.20
Note that dog has the highest similarity value, which is what we would hope for since the image is of a dog.
But do the cat and misc values seem low enough compared to the dog value?
Well, looking at the CLIP codebase we can see that softmax with a temperature parameter is used on the cosine similarities. We can use this to turn the above values into probabilities:
logit_scale = model.logit_scale.exp().item()
distances = logit_scale * torch.tensor(
[dog_similarity, cat_similarity, misc_similarity]
)
softmaxed_distances = distances.exp() / distances.exp().sum()
print(f"{logit_scale = }")
print(f"{softmaxed_distances = }")
for x, distance in zip(["dog", "cat", "misc"], softmaxed_distances):
print(f"{x} similarity: {distance.item():.4f}")
logit_scale = 100.0
softmaxed_distances = tensor([ 0.9990, 0.0005, 0.0005])
dog similarity: 0.9990
cat similarity: 0.0005
misc similarity: 0.0005
Note that we don’t need to do this softmax stuff for our search purposes, since we just care about the relative sizes of the values, which is preserved, (e.g. the dog was still the max value before the softmax) - but it helps makes the results more interpretable.
Now, how can we use this technology to carry out semantic search over video?…
Download a video
Let’s grab a video that has varied visual content (since we’re ignoring audio). (It’s a compilation of Buster Keaton stunts, check it out.)
video_path = data_dir / 'buster_keaton.mp4'
if not video_path.is_file():
!yt-dlp -f 133 -o {video_path} \
'https://www.youtube.com/watch?v=frYIj2FGmMA'
Convert the video into CLIP vectors
Use OpenCV (cv2) to process the video.
cap = cv2.VideoCapture(str(video_path))
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
print(f"{frame_count = }")
print(f"{fps = }")
print(
f"video size: {cap.get(cv2.CAP_PROP_FRAME_WIDTH):.0f}w {cap.get(cv2.CAP_PROP_FRAME_HEIGHT):.0f}h"
)
frame_count = 7465
fps = 24
video size: 426w 240h
Iterate through all frames in the video, and convert them into CLIP vectors:
image_vectors = torch.zeros((frame_count, 512), device=device)
for i in tqdm(range(frame_count)):
ret, frame = cap.read()
with torch.no_grad():
image_vectors[i] = model.encode_image(
preprocess(Image.fromarray(frame)).unsqueeze(0).to(device)
)
100%|██████████| 7465/7465 [01:17<00:00, 96.33it/s]
Most of the work was done here.
Next we create a function that will convert a “query” (i.e. a piece of text) into a vector, and look for the most similar video frames.
def get_most_similar_frame(query: str) -> tuple[int, list[float]]:
query_vector = model.encode_text(clip.tokenize([query]).to(device))
similarities = torch.cosine_similarity(image_vectors, query_vector)
index = similarities.argmax().item()
return index, similarities.squeeze()
def display_frame(index: int):
cap.set(cv2.CAP_PROP_POS_FRAMES, index)
ret, frame = cap.read()
display(Image.fromarray(frame))
def plot_search(query, similarities):
plt.figure(figsize=(8, 4))
plt.plot((logit_scale * similarities).softmax(dim=0).tolist())
plt.title(f"Search of video frames for '{query}'")
plt.xlabel("Frame number")
plt.ylabel("Query-frame similarity (softmaxed)")
plt.show()
Results
query = "A man sitting on the front of a train"
frame, similarities = get_most_similar_frame(query)
display_frame(frame)
plot_search(query, similarities)

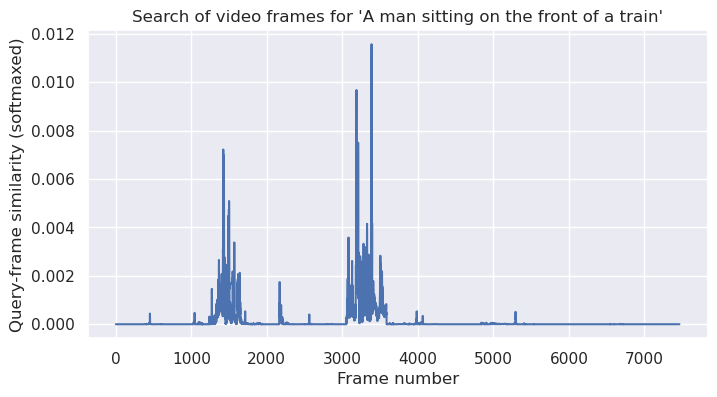
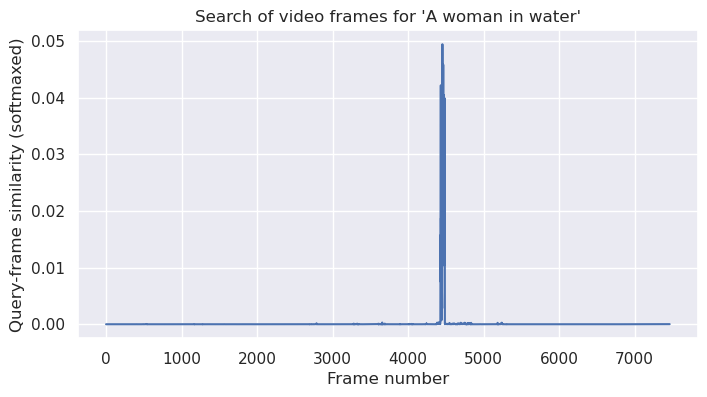
query = "A woman in water"
frame, similarities = get_most_similar_frame(query)
display_frame(frame)
plot_search(query, similarities)

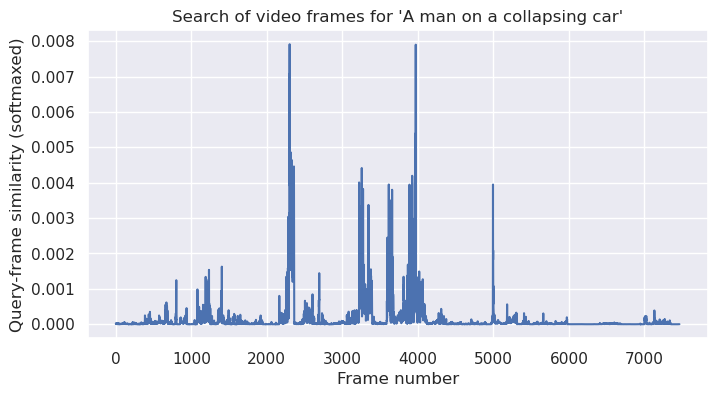
query = "A man on a collapsing car"
frame, similarities = get_most_similar_frame(query)
display_frame(frame)
plot_search(query, similarities)

query = "A woman and man hanging in front of a waterfall"
frame, similarities = get_most_similar_frame(query)
display_frame(frame)
plot_search(query, similarities)

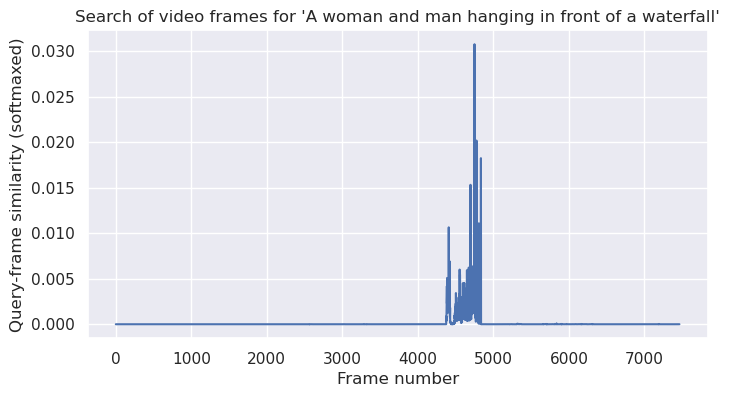
While there is room for improvement, our current approach has yielded surprisingly good results. Of course, we owe much of our success to the CLIP model.